
Hören Sie die Folge und kommentieren Sie zum Thema "Quantitative Risikoanalyse im Bauwesen":

Zusammenfassung
In dieser fesselnden Folge von „Concretely“ diskutieren wir mit dem Risikoexperten Dr. Paul-Remo Wagner, über die Bedeutung und Herausforderungen der quantitativen Risikoanalyse. Wir beleuchten, wie Ingenieure lernen müssen, das ständige Vorhandensein von Risiken zu akzeptieren, und wie Kunden über die vorhandenen Daten und Analysemöglichkeiten aufgeklärt werden können. Ein wichtiger Aspekt ist dabei die Kommunikation mit den Kunden. Die Episode bietet aufschlussreiche Einblicke in die Praxis der Risikoanalyse im Bauwesen, illustriert anhand verschiedener Projektbeispiele.
Transkript
Johannes: Willkommen bei Concretely.
Ich bin euer Host, Johannes Lohner, und ich unterhalte mich mit Experten aus unterschiedlichen Fachbereichen über den Erhalt unserer Bauwerke.
Heute geht es um die quantitative Risikoanalyse. Dabei reden wir mit Dr. Paul-Remo Wagner von der Firma Matrisk. Remo ist der Experte für Risikomodellierung. Die Firma Matrisk wurde 2004 von vier Partnern gegründet, wovon drei Professuren an technischen Hochschulen in Europa haben. Willkommen, Paul.
Paul-Remo: Hallo, ja. Danke vielmals für die Einladung. Ich freue mich, heute hier mit dir zu reden.
Johannes: Kannst du uns vielleicht kurz erklären, was Matrisk ihren Kunden anbietet?
Paul-Remo: Ja, also ich glaube, es ist schwierig, das so ganz knapp zusammenzufassen, aber ich denke, eine Möglichkeit wäre zu sagen, dass unser Fokus auf der quantitativen Risikoanalyse liegt. Und das heißt konkret, dass wir beim Erstellen von Risikoanalysen versuchen – wenn es darum geht, meist negative Auswirkungen von Systemen unserer Kunden zu beurteilen –, dann versuchen wir das immer quantitativ zu machen, das heißt, Zahlen an die Beurteilung zu hängen. Zahlen meistens in Form von Kosten pro Jahr, was der typisch ökonomische Ansatz ist: was kostet es uns, wenn wir eine Bahnstrecke oder Brücke betreiben, und dabei aber berücksichtigen, dass diese Brücke und diese Struktur ausfallen kann, Instandsetzungsmaßnahmen braucht und so weiter. Und aber auch in gewissen Systemen, in gewissen Fällen, geht es auch darum, den Todesfall von Menschen, von Benutzern dieser Strukturen, auch zu berücksichtigen in dieser ganzen Analyse. Also das Wichtige, warum quantitative Sachen überhaupt wichtig sind. Vielleicht ist das noch irgendwie wichtig. Weil es gibt die qualitativen Ansätze, wo man versucht, diese negativen Konsequenzen, also den Ausfall von irgendwelchen Sachen, zu vermeiden. Also man setzt Maßnahmen, um sowas zu umschiffen. Bei quantitativen Sachen geht es darum, wir erkennen an, dass diese Sachen nicht vermeidbar sind, und versuchen dann zu sagen: Ok, wenn diese Sachen nicht vermeidbar sind, dann stellen wir einmal sicher, dass sie möglichst selten auftreten, und dann sagen wir aber auch, wie selten sie auftreten, um das dann eben einordnen zu können.
Johannes: Steht deswegen auf eurer Homepage, dass ihr Bayesianer seid, vom Bayes’schen Theorem, oder woher kommt das?
Paul-Remo: Das steht drauf, weil wir mit Bayes’schen Methoden arbeiten, das kommt vom Bayes’schen Theorem, ja, aber es gibt auch Bayes’sche statistische Verfahren. Und die sind extrem gut dafür geeignet, Expertenwissen, was ja im Ingenieurwesen extrem häufig vorkommt, zu kombinieren mit Daten. Also Daten zu kombinieren mit Expertenwissen, das ist so eine der Dinge, wofür der Bayes’sche Ansatz sich echt gut eignet.
Johannes: Da vielleicht eine Zwischenfrage, stößt ihr da manchmal an Konflikte, weil die Erfahrung so viel zählt, und wenn man dann kommt mit Daten und Statistik und vielleicht dann mal aufzeigt, dass in manchen Fällen Erfahrungen falsch liegen oder anders liegen? Gibt’s da Konflikte mit Ingenieuren, oder habt ihr manchmal Probleme, diese zu überzeugen?
Paul-Remo: Konflikte würde ich jetzt noch nicht nennen, ich würde mal sagen, so Meinungsverschiedenheiten oder Verständnisschwierigkeiten. Das würde ich sagen, ist eigentlich das, was am häufigsten in der Beziehung auftritt. Da spielen viele Sachen rein, aber auch dieser Ansatz, dass man Probleme, ich sag jetzt mal, probabilistisch behandelt. Das heißt eben nicht nur mit fixen Werten rechnet und vermeidet, dass etwas passiert, sondern eben anerkennt, dass etwas passieren kann, und diese Eintrittswahrscheinlichkeit minimiert. Das ist schon ein Ansatz, mit dem viele Ingenieure Mühe haben, würde ich sagen. Also, aber auch verständlicherweise natürlich, weil man ja in vielen Ingenieursanwendungen diese Vereinfachungen, die so eine deterministische Behandlung in Wahrheit sind, machen muss, um die Probleme irgendwie bewältigbar zu machen. Aber klar, manchmal würden wir uns dann schon wünschen, dass ein bisschen größeres Verständnis auch da wäre, für eine Aufweitung dieser Ansichtsweise. In gewissen Fällen, also gewissen Spezialfällen, wo dann so eine deterministische Sicht oder rein Expertenwissen betriebene Sicht ohne die Berücksichtigung neuer Erkenntnisse von Daten und so weiter. Wo wir uns dann wünschen würden, dass diese vielleicht mehr aufgenommen werden, das vielleicht schon, ja.
Johannes: Wie ist das, du hast vorher erwähnt, dass ihr das quantifiziert auch im Fall von Menschen und Todesfällen. Wie kann man einen Todesfall oder ein Menschenleben quantifizieren in solchen Analysen?
Paul-Remo: Ja, das ist eine ganz schwierige Frage. Das sind wir einerseits natürlich die falschen Leute. Ich glaube, die Debatte, Menschen zu quantifizieren, das kannst du mit Philosophen, auf einer ethischen Ebene, jahrelang diskutieren. Bei uns ist es dann schlussendlich immer von Fall zu Fall unterschiedlich. Ich kann jetzt auch keine Summen nennen, das wäre erstens unprofessionell und zweitens auch falsch. Aber wenn man sich der Debatte irgendwie annähert und das überlegt, dann muss man sich auch bewusst sein, dass wir immer irgendwelche Risiken eingehen. Wir gehen eben gewisse Risiken ein, ohne uns da genau Gedanken darüber zu machen, wie groß die Risiken dann wirklich sind. Also wir steigen alle ins Auto, fahren mit dem Zug, Flugzeug, und wir wissen genau, dass diese Sachen nicht zu 100% sicher sind, dass immer irgendwas passieren kann. Aber deswegen ist man sich dann deswegen nie bewusst, dass auch ein sicheres Bauwerk eine gewisse Versagenswahrscheinlichkeit hat. Und wenn diese Versagenswahrscheinlichkeit jetzt sehr niedrig liegt, also alle 1000 Jahre, dann akzeptieren wir das einfach, weil die Alternative wäre, diese Bauwerke so zu dimensionieren, dass das gesellschaftlich auf Probleme stößt. Also wenn du eine Brücke so auslegst, dass sie auf gar keinen Fall einstürzt, also unter keiner vorstellbaren Last, dann können wir eine Brücke pro Jahr bauen und das weltweit, und das war’s. Also man muss halt dann irgendwo ein Trade-off finden, und das Menschenleben spielt da genauso hinein.
Johannes: Aktuell wird das wahrscheinlich in den nächsten Jahren, wo die Infrastruktur in Europa und den USA, also in Industrieländern, so alt wird, oder?
Paul-Remo: Absolut, absolut, also das ist sicher ein wichtiges Thema.
Johannes: Vielleicht kannst du ein paar Beispiele nennen, du hast schon das Brückenbeispiel erwähnt, wo ihr euren Kunden Mehrwert gebracht habt?
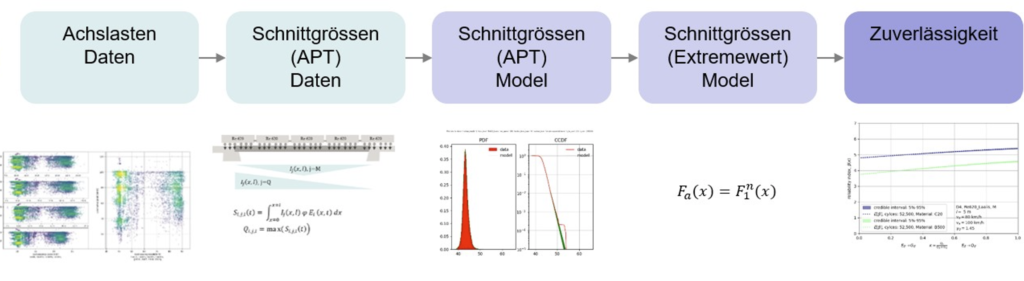
Paul-Remo: Ja gerne, also Anwendungen von diesen Risikoanalysen. Also ein Beispiel habe ich schon erwähnt, oder? Wir haben ein ganz cooles Projekt gehabt, gemeinsam mit der SBB, wo wir, basierend auf Radlastmessungen von verschiedenen Eisenbahn-Waggons an verschiedenen Stellen in der Schweiz, Daten bekommen haben von der SBB. Und wir konnten mit diesen Daten ein probabilistisches Lastmodell zusammenbauen, das heißt, eine Verteilung mit der Belastungen, die auf so einer Brücke typischerweise auftreten. Und dann haben wir dieses Lastmodell genommen und haben, basierend auf einem vereinfachten Modell für verschiedene Brücken in der Schweiz, geschaut, wie sicher ist denn das Portfolio der SBB, das Brückenportfolio der SBB, in Bezug auf die Versagenswahrscheinlichkeit mit diesen Lasten. Und das war ziemlich interessant anzusehen. Erstens weil es gibt sogar noch bei gewissen Brückentypen noch Reserven, wo die Verkehrlasten, natürlich noch mit genauerer Analyse, aber basierend auf diesen ersten Schritten, wäre es möglich, sogar noch die Verkehrslasten zu erhöhen. Und damit eine höhere Auslastung auf diesen Brücken zu erlauben. Und mit dieser populistischen Analyse war das möglich. Das so zu Brücken.
Und dann hatten wir auch noch ein cooles Projekt, gemeinsam mit der Vereinigung Kantonaler Feuerversicherungen (VKF), das läuft immer noch. Das ist auch jetzt gerade noch in der heißen Phase, wo es darum geht, dass der Brandschutz in der Schweiz, der ja kantonal sehr unterschiedlich geregelt ist, vereinheitlicht wird. Also nicht nur wir, das ist ein großes Konsortium, aber wir sind die Experten für den risikobasierten Ansatz und da geht es auch darum zu bestimmen. Also erstens mal, basierend auf Daten, wie oft brennt es denn überhaupt und wo brennt es in welcher Art von Gebäuden. Und nachher dann, wenn wir wissen, wie oft es irgendwo brennt, wie effizient sind gewisse Brandschutzmaßnahmen. Also wir versuchen zu beurteilen, wie effizient gewisse Maßnahmen, im Bezug darauf, die Brandentwicklung einzudämmen, tatsächlich sind. Und das auch in Form von quantitativer Risikoreduktion. Das heißt, wenn du eine Maßnahme einsetzt, um wie viel Schaden reduziert sich das Risiko. Und wenn du das machst, dann hast du ein Tool in der Hand, um nachher zu bewerten, wie viel darf so eine Maßnahme kosten. Und das ist ein mega spannender Fall, weil im Brandschutz gibt es immer sehr viele verschiedene Maßnahmen, die aber noch nie so richtig gerankt wurden in ihrer Effizienz. Und das wäre ein Outcome, an dem wir gerade sehr intensiv arbeiten und der einen großen Mehrwert bieten würde, nicht nur für den VKF, sondern ich denke auch für den gesamten Brandschutz in der Schweiz.
Ja und dann noch ein drittes Projekt, vielleicht wieder mehr zur Infrastruktur. Wir haben gerade ein großes Projekt am Laufen, wo es darum geht, für Offshore-Windanlagen, nicht so sehr in der Schweiz, da haben wir nicht so viel, aber in der Nordsee/Ostsee, entwickeln wir Software für probabilistische Digital Twins. Da geht es darum, Strukturen zu modellieren. Aber nicht deterministisch, sondern probabilistisch, um die Unsicherheiten in diesen Strukturen abzubilden und das gekoppelt mit optimalen risikobasierten Inspektionsplänen. Das heißt, wie oft soll man diese Strukturen untersuchen. Das heißt, wo schaut man genau hin und untersucht. Und ja, da sind wir jetzt auch gerade dran und das Ziel ist es natürlich, einen günstigeren Betrieb zu ermöglichen, einerseits, und aber auch die Lebenszeit von diesen Windfarmen unter Umständen zu verlängern, je nach Lasten, die schon aufgetreten sind.
Johannes: Das sind sehr spannende Themen.
Paul-Remo: Ja, ja, das finde ich auch.
Johannes: Kannst du den Zuhörern und mir vielleicht Schritt für Schritt erklären, wie so ein Projekt zur quantitativen Risikoanalyse abläuft, wenn man das allgemein sagen kann?
Paul-Remo: Ja, das ist nicht so einfach. Also, das Vorgehen zu verallgemeinern, ist schwierig, aber eben, ich denke also, der erste Schritt, der immer, der zieht sich eigentlich durch jedes Projekt, ist der wichtigste Schritt, dass wir gemeinsam mit den Kunden, die natürlich in den verschiedenen Anwendungen einfach die Experten sind, also relativ zu uns. Wir sind Risikoexperten, aber wir sind keine Experten für Brandschutz, keine Experten für Brückenbau und keine Experten für Offshore-Wind, und darum ist es für uns immer so wichtig, dass sie uns die Informationen, die sie haben, mitteilen. Und das ist vor allem deswegen schwierig, weil probabilistische Ansätze oder quantitative Risiko Sachen sind nicht das tägliche Brot von Ingenieuren in vielen Fällen, und es ist da oft extrem wichtig, und es ist meistens wichtig, von Anfang an da reinzugehen, und zu erklären, was wir machen. Und dann auch das Wissen, dass die Ingenieure oft besitzen, sich aber gar nicht darüber im Klaren sind, dass sie eben ganz viele Daten haben für gewisse Sachen oder sich nicht bewusst sind, dass sie in der Lage sind, nach einer kurzen Einführung, sage ich mal, diese Phänomene probabilistisch von sich aus zu modellieren. Und darum ist die Sondierung, würde ich sagen, der erste und wichtige Schritt. Also, im Beispiel für das SBB-Projekt da konnten wir das Lastenmodell entwickeln, um die Verkehrslasten auf den Brücken abzubilden, und wir haben keine eigene Daten, keine Daten-Sammelaktion dafür begonnen. Sondern das war tatsächlich so, dass die SBB ohnehin, aber für also ohnehin, ein Radlast-Messsystem auf ihrem Netz betreibt und das auf ganz anderen Gründen. Also, da geht es darum, die Bahnen auszuspuren, wenn sie zu schwer sind für gewisse Streckenabschnitte. Und sie sammeln auch all diese Daten, was super ist und auch nicht selbstverständlich ist. Oft werden Daten irgendwie immer noch ein bisschen als Übel betrachtet, das man ab und zu mal löschen muss, aber das war wirklich super, dass sie das nicht gemacht haben und uns das zur Verfügung gestellt haben. Und wir hatten damit einen Goldschatz an Daten, die wir dann verwenden konnten, und das war super.
Johannes: Das waren die Lasten der Bahnen, die über die Brücke fahren, oder wie?
Paul-Remo: Ja genau, die Daten, die sie gesammelt haben, waren Radlasten-Messungen, nicht nur für Brücken, sondern auch für andere kritische Streckenabschnitte, wo einfach eine gewisse Maximallast zulässig ist. Die haben so ein Sicherheitssystem, wo sie sagen, ab einer gewissen Last, darf ein Zug nicht weiterfahren. Und sie haben Daten von jedem Zug, der drüberfährt, das waren über 2 Millionen Radlastmessungen.
Johannes: Nicht schlecht, ok…
Paul-Remo: Ja, und dann eben der nächste Schritt, nachdem man halt mal das Problem erarbeitet hat. Das kommt dann auch oft aus solchen Gesprächen heraus, dass man sich am Anfang noch gar nicht so bewusst ist, was das Problem, die Problemstellung, genau ist. Bei uns kommt dann meistens als Nächstes die Modellbildung. Also, das heißt, wir entwickeln für das konkrete Problem ein Modell, das ist jetzt z.B. in diesem SBB-Fall ein Lastmodell, basierend auf diesen Daten (ein rein datenbasiertes Lastmodell), gekoppelt mit dem vereinfachten Strukturmodell der Brücken, und damit können wir dann unsere Analyse starten. Was da vielleicht noch wichtig ist bei der Modellbildung, ich hab es vorhin schon gesagt, mit den probabilistischen Modellen. Es ist bei der Modellbildung, bei uns oft so, also generell, nicht nur bei uns als Firma, sondern es ist tatsächlich oft so im Ingenieurwesen, dass wir gewisse Eingabegrößen in Modelle gar nicht so genau kennen. Also, das sind jetzt hier die Verkehrslasten, das ist der perfekte Fall. Wir wissen nicht genau, wie schwer welcher Zug ist, der über die Brücke fährt. Und mit probabilistischen Modellen kann man das irgendwo berücksichtigen. Also statt, dass man hier einfach einen Extremfall des Zuges modelliert, was der typische Fallansatz ist, modelliert man diesen Zug einfach als unsicher, also „ungewiss“ ist eigentlich die richtige Übersetzung von ‚uncertainty‘, modelliert dann diese Größen einfach als nicht ganz spezifisch bekannt und schaut dann, wie sich diese Unsicherheiten durch die Modelle fortpflanzen, also welche Auswirkungen das dann in dem Fall auf die Spannungen in der Brücke hat, wenn man die Verkehrslasten als unsicher betrachtet. Und diese Unsicherheiten dann berücksichtigt, und das nicht nur auf der Einwirkungsseite, also das sind in dem Fall jetzt die Lasten, sondern auch auf der Widerstandsseite. Also wir wissen ja auch aus den Materialwissenschaften, dass die Fließgrenze von Stahl zum Beispiel. Also Stahl ist relativ sicher, aber auch dort gibt es Unsicherheiten in den Materialmodellen. Aber Beton z.B., der Widerstand von Beton ist nicht immer gleich, also wie man so schön sagt, der streut extrem. Und das kann man mit probabilistischen Modellen berücksichtigen. Und das Ergebnis von so einem Modell ist dann eben nicht, dass eine Brücke versagt oder nicht versagt, wenn sie falsch dimensioniert ist oder wenn schwere Lasten drüber fahren, sondern das Ergebnis ist eine Versagenswahrscheinlichkeit. Also wir können nachher sagen, mit einer gewissen Wahrscheinlichkeit versagt die Brücke, und können dann so viel breitere Fälle abdecken als nur einen Extremwert anzuschauen.
Ja genau das zur Modellbildung, und da ist es auch noch wichtig, das Modell auch noch zu kalibrieren. Also, da ist es noch wichtig, dass man mit Daten arbeitet, um entweder direkt Eingabeparameter zu modellieren oder, die klassische Kalibrierung geht dann soweit, dass man sich Ausgaben des Modells ansieht und andere Daten nimmt, um die Ausgaben mit den Daten abzugleichen. Da gibt es verschiedene Ansätze dafür. Das kann man probabilistisch oder deterministisch machen. Da gibt es ganz viele Möglichkeiten und eben auch hier, das haben wir vorher schon kurz angesprochen, die Bayes’schen Methoden sind ja auch so ein wichtiges Tool für die Modellkalibrierung. Und die Modellkalibrierung ist ein klassischer Fall, wo man mit Expertenwissen, also von bestehendem Wissen über Unsicherheiten, die dann oft Ingenieuren bekannt sind, arbeitet. Also, wenn man sie dann fragt, ihr habt eine Materialfestigkeit, wisst ihr denn genau, wie groß die ist? Das wissen sie dann oft nicht. Aber wenn du sie fragst, könnt ihr uns eine Range geben, also Minimal- und Maximalwerte, das ist dann sehr oft bekannt. Und das können wir dann verwenden, um das probabilistisch zu modellieren. Und dann auch das zu verwenden, um es zu kalibrieren.
Johannes: Dann kalibriert ihr das Modell im Nachhinein und passt es so an, dass es den Erwartungen und Ergebnissen entspricht. Für mich klingt es ein bisschen wie supervised learning aus dem Machine Learning-Bereich. Kann man das vergleichen?
Paul-Remo: Ja, das sicher. Also das ’supervised learning‘ ist im Prinzip ja das ‚Training‘ eigentlich. Das ‚Training‘ von Modellen bei Machine Learning-Modellen ist im Prinzip nichts anderes. Dort werden halt dann die Eingaben ins Modell und die Ausgaben, im Fall von Machine Learning dann halt die ‚gelabelten‘ Eingabe-Daten, genommen. Dann wird das Modell trainiert, und das heißt nichts anderes, als dass man die Parameter dieser Modelle, die oft sehr, sehr viel mehr Parameter haben als unsere Modelle, also viel mehr, hunderttausende und so weiter, dass man die anpasst und trainiert, oder kalibriert, kann man auch sagen. Aber der Hauptunterschied ist eigentlich, dass unsere Modelle oft niedriger dimensional sind, also viel weniger Parameter haben, aber dafür viel teurer, also im Sinne von, wenn du ein Strukturmodell hast von einer Brücke, die sind halt sehr rechenintensiv. Es kann sein, je nachdem, was für ein Modell du hast, dass so ein Finite-Elemente-Modell (FE-Modell) von einer Brücke stunden- oder tagelang rechnet. Dafür gibt’s dann eben Ansätze, um auch solche teuren Modelle zu modellieren. Das sind auch Dinge, die wir machen. Also zum Beispiel Stichwort Ersatz-Modellierung, ‚Surrogate Model‘ auf Englisch.
Also dann, wenn das Modell kalibriert ist, dann ist aber eben auch noch mal ganz wichtig, dass wir mit dem Modell, mit dem kalibrierten Modell, wieder zu unseren Kunden gehen. Und noch mal wie einen zweiten Schritt machen, um deren Wissen nochmals abzuholen und auch um eine gewisse Glaubwürdigkeit für das Modell zu erhalten. Weil schlussendlich sind Modelle nur Modelle. Sind nie mehr als Modelle. Sie haben ihren Nutzen in dem Bereich, aber entsprechen nicht der Realität. Und darum ist es extrem wichtig, dass man da mit den Kunden gemeinsam dann noch mal hineingeht und im Detail schaut, wo vielleicht Missverständnisse vorliegen oder auch nicht, oder wo dem Kunden bereits hier Mehrwert gebracht wurde. Und darum ist dieser Iterationsschritt etwas ganz, ganz Wichtiges.
Johannes: Ok, also das waren alle Schritte?
Paul-Remo: Ja, soll ich es noch einmal zusammenfassen?
Johannes: Vielleicht fasse ich zusammen, aus meinem Verständnis: Also zuerst die Sondierung, da geht’s darum, die Daten zu sammeln. Das stelle ich mir sehr komplex vor, weil der Kunde nicht immer genau weiß, welche Daten notwendig sind und was überhaupt alles zur Verfügung steht. Der zweite Schritt ist die Modellbildung. Anschließend die Modellkalibrierung, wo alles noch einmal zusammengefügt wird und geschaut wird, dass das Modell richtig funktioniert und an die Daten angepasst ist. Und dann der letzte Schritt, noch einmal iterativ zum Kunden gehen, noch einmal abgleichen, besprechen und erklären. Ist das richtig?
Paul-Remo: Ja genau, und dann am Schluss natürlich noch die Resultate generieren. Das ist ja dann das eigentliche Ziel: die Vorhersagen oder die Handlungsempfehlungen. Das ist das, wo das Modell dann wirklich zum Einsatz kommt. Es ermöglicht eine quantitative Risikoanalyse zu machen und zu sagen: Ok, basierend auf dem Modell ist es am sinnvollsten, das zu machen oder das und das zu unterlassen.
Johannes: Ok, vielleicht grundsätzlich. Braucht es immer ein Modell für die quantitative Risikoanalyse oder reicht manchmal auch die Daten zu analysieren?
Paul-Remo: Ja, also grundsätzlich hängt es davon ab, was man mit Modell meint. Es gibt ja auch rein datengetriebene Modelle, bei denen man den gesamten Prozess der Modellbildung nicht durchläuft, sondern einfach Daten erhält und darauf basierend ein Modell entwickelt.
Es gibt jedoch einige Probleme bei unseren Anwendungen. Das erste ist sicherlich, dass wir oft einfach keine Daten haben oder nicht so viele Daten, wie wir bräuchten. Das ändert sich zurzeit, also da ist ein klarer Trend in diese Richtung. Das Bewusstsein für den Wert von Daten steigt. Es ist aber nicht für alle Anwendungen erstens wirklich etabliert und zweitens auch nicht überall möglich. Also zum Beispiel bei einer Brücke, um wieder auf Brücken zurückzukommen: Wenn du eine Brücke hast, die ja ein Einzelbauwerk ist, ist es je nach Fragestellung schwierig, das rein datenbasiert zu machen. Das heißt nicht, dass man es nicht probabilistisch machen kann, aber rein datenbasiert ist es schwierig. Deswegen ist eine Modellbildung, so wie wir sie verstehen, sehr wichtig. Die zweite Sache für rein datenbasierte Ansätze ist, dass wir oft mit sogenannten Tail-Events arbeiten. Also es geht um seltene Ereignisse, also um hohe Lasten, niedrige Materialfestigkeiten. Das ist der Bereich, wo wir Risikoanalysen machen, und rein datenbasiert braucht es einfach sehr lange, um rein statistisch diese seltenen Ereignisse zu erfassen. Daher ist irgendeine Form von Modellbildung in den meisten Fällen auch unerlässlich.
Johannes: Was sind die größten Herausforderungen bei den Projekten?
Paul-Remo: Ja, also ich glaube, die größten Herausforderungen sind in meiner Erfahrung nicht unbedingt technischer Art. Also nicht die Arbeit, die wir an sich machen, sondern die Kommunikation, sowohl im Anlauf eines Projekts, also in dieser Sondierungsphase, wo es darum geht zu verstehen oder zu vermitteln, wo wir den Mehrwert bieten können. Und dann auch wieder in der Kommunikation der Resultate. Einerseits weil in der Validierung einfach sehr viel mehr Wissen abgeholt werden kann, wenn man den Kunden mit einbezieht. Das habe ich vorher schon gesagt: Wir sind keine Experten in den einzelnen Feldern, die wir betreuen. Wir sind Risikoexperten und sind daher stark angewiesen auf das Fachwissen der Kunden in den einzelnen Bereichen. Und da sind oft die Schwierigkeiten in Bezug auf die Kommunikation und auf die Wortwahl, und wie man erklärt, was man eigentlich macht. Das sind die Herausforderungen.
Johannes: Dankeschön fürs Zuhören. Bitte teile deine Meinung im Kommentarbereich der Folge auf meiner Homepage www.concrete-ly.com. Sehr gerne könnt ihr auch persönliche Erfahrungen oder Beschwerden hinterlassen. Bitte „like“ und teile den Podcast mit deinen Freunden und Kollegen, auch über Spotify oder Apple Music. Übrigens, die Folgen sind auf der Homepage auch auf Englisch übersetzt.
Literatur und Referenzen
- ESA Handbuch: handbook.reliability.space insbesondere Abschnitt 6
- JCSS
- ETH Vorlesungen
- Book: Bayesian Data Analysis